本文主要关心一些性能优化小技巧——“微优化”,这些技巧并不一定给你的应用带来令人激动人心的性能提升,但是把这些技巧结合起来使用,也会给你的应用带来一些性能上的提高。在性能优化方面,选择正确的算法和数据结构永远是你的第一选择,但是这不是本文所要介绍的重点。你应该把本文所提到技巧运用到日常的开发中,并努力使其成为你的编码习惯的一部分。
翻译自:http://developer.android.com/training/articles/perf-tips.html
编写高效代码有两个基本原则:
- 不要写没用的逻辑,不要执行你不需要的代码。
- 如果能避免使用内存,那就不要使用内存。
我们在“微优化”一个Android App时,会面临一个最苦逼问题就是,你的应用会跑在不用的硬件平台上。不同的虚拟机运行在不同的处理器上,而且处理器的速度也不一样。所以,不能简单地说“设备X一定比设备Y慢或者快多少”,尤其在模拟器上的测试结果,并不能反映在真机设备上的真实性能。另外,用不用JIT在不同的设备上也有很大差异:运行在JIT上的代码也并不总是比没有JIT的设备运行的更好。
要想使你的程序能在更多平台上运行良好,就要确保你的代码在所有层面上都是高效的并且尽一切可能优化你的性能。
避免创建无用对象
对象从来都不是可以随便创建的。但是临时对象的内存分配比较廉价,但是分配内存总是要不分配要付出更大的代价。
如果你在你的应用中创建了很多对象,你就必须周期性地进行垃圾回收,这就会给你的用户带来一种“打嗝”(卡顿)的感觉。虽然在Android 2.3中引入的并行垃圾回收器会这个缓解这个问题,但是还是那句老话,能不分配还是尽量别分配。
因此,没必要创建对象时就要避免创建它,下面的几个列子对你会有所帮助:
- 如果你有一个方法返回一个字符串作为结果,而且这个结果会总是会append给一个StringBuffer,那么请改变你的实现方式,让你这个方法直接做append,而不是多创建一个短命的临时对象。
译者注:我猜他可能要说是这种情况,如果没猜对,欢迎大家来拍砖啊,呵呵:
变成:String timestr(){ return " 20:09:11"; } StringBuffer sb = new StringBuffer(); sb.append("2013 "); String time = timestr(); sb.append(time);这样就创建了一个 time对象StringBuffer sb = new StringBuffer(); sb.append("2013 "); sb.append(timestr()); - 当我们从一个输入数据集中抽取一个字符串的时候,尝试返回一个原始数据的子串,而不是创建一份拷贝。这样虽然你创建了一个String类型的对象,但是他和原始数据是共享内存中的char[]。(不过这样做的前提你还要权衡一下原始数据的规模和场景,如果你这样做了,那么内存中原始数据会多了一个引用,可能不利于数据的回收,总之,这样做友好有坏,代价自己把握)。
译者注:让我们做个简单实验就知道了, 代码:
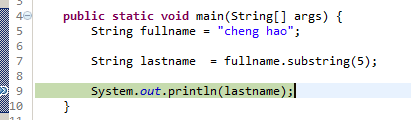
我们通过eclipse的variables窗口看到的内容:
可见 lastname 和 fullname 同享相同的内存区域,lastname只不是是通过offset控制字符串的起始位置。
还有一些更为极端的做法,比如把一个多维数组分解成为多个一维数组:
- 一个int类型(原始类型)的数组总是要好过Integer(对象类型)类型的数组。两个一维数组要比一个(int,int)类型的数据更高效。这个原则同样适用于其他原始类型。
译者注,举个例子: 代码:

我们通过eclipse的variables窗口中会看到: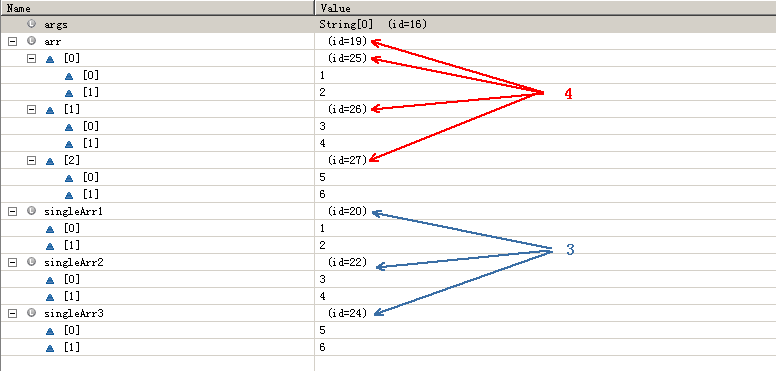
使用多个一维数组会比使用多位数组创建更少的对象. - 如果你需要创建一个二元对象的容器,比如(Foo,Bar),那么同上文所述,创建两个类型分别为Foo 和 Bar的一维数组更为高效。(也有类外的情况,比如你在为其他代码设计API的时候,为了达到一个好的设计和可读效果,往往需要在效率上做一点点的妥协。不过在写你自己的代码的时候,还是要尽可能利用更高效的方法)。
静态化要由于虚拟化
如果类中的一个方法不需要访问类中的其他成员,那么最好把它声明为static的,这样会使得该方法被调用的速度快15%-20%(译者注:这里可以参考之前的一篇文章《Java中static、private、public 方法哪个更快》)。这是一个很好的做法,因为静态方法不会改变对象的状态,虚拟机会很快地搜索到该方法。
使用 static 、final 声明常量
看下面两段代码:
static int intVal = 42;
static String strVal = "Hello, world!";
针对这段代码,编译器会产生一个“类构造函数”,叫做<clinit>,这个构造函数会在类被第一次使用时执行(译者注:intVal的地址引用中,并将strVal指向类文件字符串常量表中的一个索引地址(即字符串“Hello, world!”的索引地址)。在访问这两个值时,需要通过“字段检索”的方式进行访问(译者注:需要先检索变量名称,然后通过变量名称来检索值,后面我们会通过字节码来加深理解)。
我们在通过final关键字再来改造一下:
static final int intVal = 42;
static final String strVal = "Hello, world!";
通过final关键字声明之后,该类就不需要<clinit>方法了,因为在dex文件中两个值会直接当作对应的常量来使用,用到intVal时,相当于直接使用整数42,用到strVal时,会使用开销相对较小的“字符串常量”指令,而不需要进行“字段检索”。
译者注:
下面我们通过具体的例子来加深一下理解:
代码1:字节码1:public class Test { static int intVal = 42; static String strVal = "Hello, world!"; public static void main(String[] args) { System.out.println(intVal); System.out.println(strVal); } }... Constant pool: #1 = Class #2 // tips/Test ... #5 = Utf8 intVal #6 = Utf8 I #7 = Utf8 strVal #8 = Utf8 Ljava/lang/String; ... #12 = Fieldref #1.#13 // tips/Test.intVal:I #13 = NameAndType #5:#6 // intVal:I #14 = String #15 // Hello, world! #15 = Utf8 Hello, world! #16 = Fieldref #1.#17 // tips/Test.strVal:Ljava/lang/String #17 = NameAndType #7:#8 // strVal:Ljava/lang/String; ... static int intVal; flags: ACC_STATIC static java.lang.String strVal; flags: ACC_STATIC static {}; 这就是 <clinit> flags: ACC_STATIC Code: stack=1, locals=0, args_size=0 0: bipush 42 2: putstatic #12 // Field intVal:I 5: ldc #14 // String Hello, world! 7: putstatic #16 // Field strVal:Ljava/lang/String; 10: return LineNumberTable: line 4: 0 line 5: 5 line 3: 10 LocalVariableTable: Start Length Slot Name Signature ... public static void main(java.lang.String[]); flags: ACC_PUBLIC, ACC_STATIC Code: stack=2, locals=1, args_size=1 0: getstatic #27 // Field java/lang/System.out:Ljava/io/PrintStream; 3: getstatic #12 // Field intVal:I 6: invokevirtual #33 // Method java/io/PrintStream.println:(I)V 9: getstatic #27 // Field java/lang/System.out:Ljava/io/PrintStream; 12: getstatic #16 // Field strVal:Ljava/lang/String; 15: invokevirtual #39 // Method java/io/PrintStream.println:(Ljava/lang/String;)V 18: return LineNumberTable: line 7: 0 line 8: 9 line 9: 18 LocalVariableTable: Start Length Slot Name Signature 0 19 0 args [Ljava/lang/String; ...代码2:字节码2:public class Test2 { static final int intVal = 42; static final String strVal = "Hello, world!"; public static void main(String[] args) { System.out.println(intVal); System.out.println(strVal); } }... Constant pool: ... #11 = String #12 // Hello, world! #12 = Utf8 Hello, world! ... static final int intVal; flags: ACC_STATIC, ACC_FINAL ConstantValue: int 42 static final java.lang.String strVal; flags: ACC_STATIC, ACC_FINAL ConstantValue: String Hello, world! ... public static void main(java.lang.String[]); flags: ACC_PUBLIC, ACC_STATIC Code: stack=2, locals=1, args_size=1 0: getstatic #24 // Field java/lang/System.out:Ljava/io/PrintStream; 3: bipush 42 5: invokevirtual #30 // Method java/io/PrintStream.println:(I)V 8: getstatic #24 // Field java/lang/System.out:Ljava/io/PrintStream; 11: ldc #11 // String Hello, world! 13: invokevirtual #36 // Method java/io/PrintStream.println:(Ljava/lang/String;)V 16: return LineNumberTable: line 8: 0 line 9: 8 line 10: 16 LocalVariableTable: Start Length Slot Name Signature 0 17 0 args [Ljava/lang/String; ...
通过对比“字节码1”和“字节码2”我们发现,在使用`final`关键字修饰两个变量之后,“字节码2”中没有了<clinit>方法(即 “字节码1”中 static {}; 开始的那几行),取而代之的是多了 ConstantValue: int 42 和 ConstantValue: String Hello, world!。
在字节码1中对 intVal 和 strVal 的应用需要反复查找常量池(Constant pool)才能找到他们的值(这个过程就是上文说的“字段检索”)。而在字节码2中,对 intVal 的引用会直接使用整数42替代(参见 bipush 42 这条指令),对 strVal 的应用也会直接定位到 “Hello, world”所在的位置(参见字节码2中 ldc #11 这条指令)
可见 final 声明测商量要比不用 final 声明的常量在执行上要快。
注意:上述优化只适用于基础类型和String类型的常量,不适用于一般的对象引用类型。但是,使用
static final来声明常量仍然是一个好习惯。
避免在类的内部使用Getters/Setters
像C++这种能够编译成本地代码的语言,用getters (i = getCount()),而不是直接访问成员变量(i = mCount)是比较常用的办法。对于C++,以及其他一些常见的面向对象语言,如C#、java,这都是一个好习惯,因为编译器通常会把这种访问内联化,而且你可以很方便的地控制或debug你的成员变量。
但是,在Android中,这不是一个好习惯。虚拟方法的调用(译者注:就是我们通常遇到的针对实例对象方法的调用,所谓虚拟化方法是相对于静态方法的,因为在字节码指令中实例方法的调用使用的是invokevirtual,静态方法使用的是 invokestatic)是很耗性能的,远远超过调用成员变量所耗的性能。遵循大家公认的编码习惯通常也是合理的,我们在对外开放(public的)的接口中使用getters/setters,但是在同一个类的内部,你就应该直接引用成员变量了。
在非JIT模式下,直接引用成员变量要比调用getter方法快3倍。在JIT模式下(对成员变量的引用跟使用本地代码的性能差不多了),直接引用成员变量要比调用getter方法快7倍。
如果你使用ProGuard(译者注:主要用于代码混淆,也会带来一些性能上的提升),那就两全其美了,因为 ProGuard 可以把 getters/setters 内联化。
优先使用Enhanced For Loop语法
Enhanced For Loop(有时也被称作 for each 循环),可以用在实现了 Iterable 接口的集合类型以及数组类型上。集合类型中,可以使用迭代器中的hasNext()和next()方法来遍历。对与ArrayList,一个显示计数器要比迭代器方式快3倍以上(有没有JIT都差不多),其他的集合类型 Enhanced For 语法和显示的迭代器方式是等价的(译者注:下面我们做个例子来体验一下这两句话的含义)。
代码1:TestArrayListSpeed_Iterator代码2:TestArrayListSpeed_Countedpublic class TestArrayListSpeed_Iterator { public static Integer tmp = null; public static void main(String[] args) { ArrayList<Integer> arr = new ArrayList<Integer>(); for (int i = 0; i < 9999999; i++) { arr.add(i); } Iterator<Integer> iterator = arr.iterator(); long start = System.currentTimeMillis(); while (iterator.hasNext()) { tmp = iterator.next(); } System.out.println(System.currentTimeMillis() - start); } }在我的Dell E6410上各执行5次后的对比情况(单位ms):public class TestArrayListSpeed_Counted { public static Integer tmp = null; public static void main(String[] args) { ArrayList<Integer> arr = new ArrayList<Integer>(); for (int i = 0; i < 9999999; i++) { arr.add(i); } long start = System.currentTimeMillis(); for (int j = 0; j < arr.size(); j++) { tmp = arr.get(j); } System.out.println(System.currentTimeMillis() - start); } }可见对于 ArrayList 类型,计数方式比迭代器方式要快得多。
代码 第1次 第2次 第3次 第4次 第5次 代码1(Iterator方式) 699 644 672 675 707 代码2(Counted方式) 162 158 137 131 141
我们再通过数组类型再举个例子:
public class TestEnhanceFor {
static class Foo {
int mSplat;
}
static final int COUNT = 49999999;
Foo[] mArray = new Foo[COUNT];
public TestEnhanceFor() {
for (int i = 0; i < COUNT; i++) {
mArray[i] = new Foo();
mArray[i].mSplat = i;
}
}
public void zero() {
int sum = 0;
for (int i = 0; i < mArray.length; ++i) {
sum += mArray[i].mSplat;
}
}
public void one() {
int sum = 0;
Foo[] localArray = mArray;
int len = localArray.length;
for (int i = 0; i < len; ++i) {
sum += localArray[i].mSplat;
}
}
public void two() {
int sum = 0;
for (Foo a : mArray) {
sum += a.mSplat;
}
}
public static void main(String[] args) {
TestEnhanceFor obj = new TestEnhanceFor();
long start = System.currentTimeMillis();
obj.zero();
// obj.one();
// obj.two();
System.out.println(System.currentTimeMillis() - start);
}
}
zero() 方法最慢,因为每次迭代都会获取数组长度,JIT对这种方式优化不了。
one() 方法相对快一些,它把数组长度保存在一个局部变量中,从而避免了彼此对数组长度的检索。不过,这只是在数组长度上做了一些优化。
two() 方法在没有JIT的设备上最快,在有JIT的设备上和方法one() 差不多。它用的就是在 Java1.5 之后引入的Enhanced For Loop语法。
译者注:我们做一下实验,看看真正的效果如何(单位毫秒)。
在我的笔记本上把这三个方法分别在使用JIT和不使用JIT的方式各跑5次的结果如下(对于Hotspot虚拟机,可以使用 -Djava.compiler=NONE 来禁用JIT功能)从结果上看,在不使用JIT的情况下,Hotspot虚拟机的运行结果中 `two()` 并没有 `one()` 快,所以我对上文的说法表示质疑。不过我是在笔记上做的测试,感兴趣的同学可以在真机上做一下测试。
方法 第1次 第2次 第3次 第4次 第5次 zero(JIT) 209 205 212 215 211 one(JIT) 165 169 180 166 169 two(JIT) 175 165 177 170 166 zero 2583 2451 2152 2146 2166 one 1013 986 970 1093 987 two 1106 1260 1320 1390 1388
所以,默认情况下优先使用 enhanced for loop 语法,只不过对于 ArrayList 类型,使用手动计数的方式获得更高的性能。
提示:你可以参考 Josh Bloch 写的《Effective Java》一书中第46条。
在私有内部类中考虑使用包访问方式(Package Access)方式,而不是私有访问的方式(Private Access)
看下面的代码:
public class Foo {
private class Inner {
void stuff() {
Foo.this.doStuff(Foo.this.mValue);
}
}
private int mValue;
public void run() {
Inner in = new Inner();
mValue = 27;
in.stuff();
}
private void doStuff(int value) {
System.out.println("Value is " + value);
}
}
这段代码的重点在于,我们定义了一个私有内部类(Foo$Inner),它能直接访问外部类的私有成员变量和私有方法。这种方式是合法的,且如你所料,会输出“Value is 27”。
问题在于虚拟机认为从 Foo$Inner 中直接访问 Foo 中的私有成员是不合法的,因为他们是两个不同的类,即使在Java语法中允许内部类访问外部类的私有成员。为了在两者之间建立起联系,编译器会自动生成一些辅助方法。
/*package*/ static int Foo.access$0(Foo foo) {
return foo.mValue;
}
/*package*/ static void Foo.access$1(Foo foo, int value) {
foo.doStuff(value);
}
译者注:这两个被编译器自动生成的方法一般的反编译工具是看不到的,但是我们可以通过 javap -v Foo 来证明它们是存在的:> javap -v Foo ... static int access$0(Foo); flags: ACC_STATIC, ACC_SYNTHETIC Code: stack=1, locals=1, args_size=1 0: aload_0 1: getfield #22 // Field mValue:I 4: ireturn LineNumberTable: line 8: 0 LocalVariableTable: Start Length Slot Name Signature static void access$1(Foo, int); flags: ACC_STATIC, ACC_SYNTHETIC Code: stack=2, locals=2, args_size=2 0: aload_0 1: iload_1 2: invokespecial #62 // Method doStuff:(I)V 5: return LineNumberTable: line 16: 0 LocalVariableTable: Start Length Slot Name Signature ...Foo$Inner 通过反编译工具(比如XJad)获得的代码是:private class Foo$Inner { final Foo this$0; void stuff() { Foo.access$1(Foo.this, Foo.access$0(Foo.this)); } private Foo$Inner() { this$0 = Foo.this; super(); } Foo$Inner(Foo$Inner foo$inner) { this(); } }
内部类实际上是通过这两个静态方法来访问到外部类的mValue和doStuff()。这意味着上面的代码是通过存取器(例如Getters/Setters)来访问成员变量的。前文中我们还提到过,通过存取器访问成员变量要比直接访问要慢,所以这个例子从某种意义上讲会造成一些“不可见”的性能影像。
如果你使用类似上面的代码,你可以避免私有访问(private access)带来的一些性能开销(译者注:以我的理解,这里说的“private access”可能是指在内部类中定义用于保存外部类的对象引用的变量,内部类在使用外部类时,需要先把外部类的实例set到内部类的实例中)。不过,这也意味着这些成员也可以被同一个包中的其他类访问到,在开发API时,这种方式要慎用。
避免使用浮点数
一般来说,在Android设备中,浮点数要比整数慢2倍左右。
在速度方面,在现在的硬件设备上,float and double 并没有差别。空间敏感的double在使用空间上比float大两倍。比如在台式机上,加上空间不是问题,你最好用double.
即使是整数,某些处理器也只是把乘法用硬件实现了,对与除法和取模操作仍然使用的是软件模拟的。
了解并使用系统库
记住,系统中自带的库,很多都是通过汇编来实现的,即使你用最好的代码在加上JIT,也比不过汇编的方式。典型的例子就是 String.indexOf()以及相关的API,Dalvik 会使用内部的实现替换之。同样,System.arraycopy()方法在 Nexus One 上要比在JIT下用手工实现的方式快9倍。
提示:可参考 Josh Bloch 所写的《Effective Java》中的第47条。
小心使用本地方法(Native Methods)
用Android NDK 开发你的App 并不总是比Java语言开发的更高效。首先,这里有从Java到Native过渡的成本,而且JIT不能跨越他们的边界进行优化。如果你分配了本地资源(比如本地堆上的内存,文件描述符、或者其他什么的),定时回收他们也会变的很困难。另外,你还要针对不通的平台来编译你的代码(而不是依赖JIT).即使是相同的平台你也可能需要编译不同的版本,比如针对G1上的ARM处理器编译的版本不能充分利用 Nexus One 上ARM功能,针对Nexus One 上ARM编译的代码也不能跑在G1的ARM处理器上。
如果你已经有了一个Native代码库,并想补充到Android系统中时,此时编写本地代码是很用的,但是不要试图把能用Java代码编写部分用本地化来加速。
如果你不得不使用Native编码,你做好参考一下 JNI Tips
提示:可参考 Josh Bloch 所写的《Effective Java》中的第54条。
性能的误解
在没有JIT的设备上,通过精准类型来应用变量的方法要比接口更高效(比如,有个变量叫 map, 我们要调用 map 的方法,map的真实类型是 HashMap, 那么把 map 声明为 HashMap map 要比声明为 Map map 的调用速度快,译者注:前者在调用方法是用的是invokevirtual指令,后者使用的事invokeinterface, invokeinterface 指令要比invokevirtual慢)。但是这并不会有数倍的性能差异,实际只会慢6%左右。此外,JIT会把这个差异优化到几乎忽略不计。
在没有JIT的设备上,缓存成员变量值会比每次都去访问成员变量值要快20%。但是在使用JIT的情况下,成员变量的访问开销堪比本地代码,除非你认为这种方式会使你的代码可读性更好,否则,这种优化没有多大意义。